how should the robots txt formatted
In the ever-evolving world of Search Engine Optimization (SEO), understanding the nuances of robots.txt is crucial for website owners and marketers. Robots.txt is a powerful tool that allows you to control how search engine crawlers interact with your website. In this comprehensive guide, we will delve into the intricacies of robots.txt, its importance, and how to use it effectively to influence your website’s indexing and visibility in search engines.
Robots.txt is a valuable tool in the SEO arsenal, allowing website owners to control how search engine crawlers interact with their sites. By understanding the fundamentals of robots txt in seo and using it strategically, you can optimize your website’s crawl budget, prevent duplicate content issues, and protect sensitive areas of your site. Implementing a well-crafted robots.txt file is a fundamental step in achieving better search engine rankings and improving the overall performance of your website in the digital landscape.
What is Robots.txt?
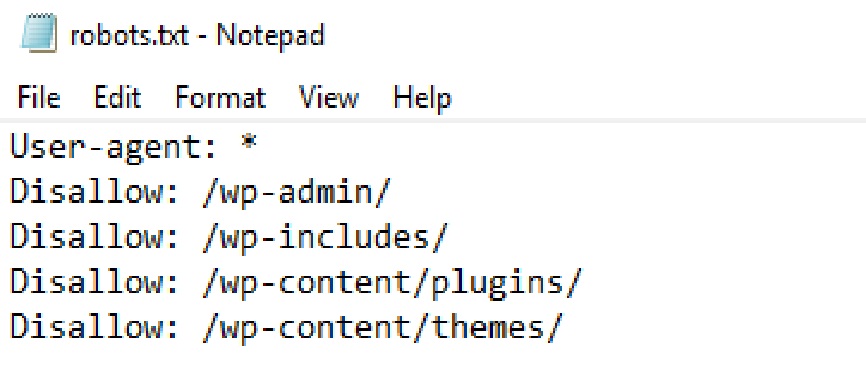
Robots.txt, short for “robots exclusion protocol,” is a text file that website owners place in the root directory of their web server. This file instructs search engine crawlers (also known as “robots” or “spiders”) about which parts of the website should be crawled and indexed and which parts should be ignored. A robots.txt file tells search engine crawlers which URLs the crawler can access on your site. This is used mainly to avoid overloading your site with requests; it is not a mechanism for keeping a web page out of Google. To keep a web page out of Google, block indexing with noindex or password-protect the page.
Why is Robots.txt Important?
Controlling the crawling behavior of search engine bots is essential for several reasons:
- Crawl Budget Optimization: Search engines allocate a certain crawl budget to each website. By using robots.txt, you can prioritize the crawling of your most important pages, ensuring they get indexed promptly.
- Preventing Duplicate Content: Robots.txt can help prevent search engines from indexing duplicate or low-value content, which can negatively affect your SEO rankings.
- Protecting Sensitive Information: You can use robots.txt to block search engines from accessing confidential or sensitive areas of your website, such as login pages or admin sections.
How to Create and Use Robots.txt
Creating a robots.txt file is a straightforward process:
- Create a Plain Text File: Open a plain text editor (like Notepad) and create a new file.
- Define Rules: In the file, specify the user-agent (the search engine bot) and the rules for how it should crawl your site. Here’s an example:
User-agent: *Disallow: /private/Allow: /public/
-
User-agent:applies the rules to all search engine bots.
*Disallowtells bots not to crawl specific directories or pages.Allowpermits crawling of specific directories or pages.
- Save the File: Save the file as “robots.txt” and upload it to the root directory of your web server.
Best Practices for Robots.txt
To make the most of your robots.txt file, follow these best practices:
- Test Your Robots.txt: Use Google’s Robots Testing Tool in Google Search Console to check if your robots.txt file is valid and properly configured.
- Be Specific: Be as specific as possible when creating rules. Avoid using broad disallow rules that may inadvertently block important content.
- Update Regularly: Regularly review and update your robots.txt file, especially if you make changes to your website’s structure or content.
- Include Sitemap Information: You can also include a reference to your XML sitemap in the robots.txt file to help search engines find and crawl your pages more efficiently.
Advanced Robots.txt Usage
While the basics of robots.txt are important, there are more advanced techniques and considerations to maximize its effectiveness:
1. Wildcards
You can use wildcards in robots.txt rules to match multiple URLs. Two common wildcards are:
*(asterisk): Matches any sequence of characters.$(dollar sign): Matches the end of a URL.
For example:
plaintextUser-agent: GooglebotDisallow: /images/*?$
This rule disallows any URLs that start with “/images/” and end with a query string, preventing Googlebot from crawling image search parameters.
2. Allow vs. Disallow
In robots.txt, “Allow” and “Disallow” rules have different effects:
- “Disallow” tells search engines not to crawl specific content.
- “Allow” can be used to override a broader “Disallow” rule for specific content.
For example:
plaintextUser-agent: *Disallow: /private/Allow: /private/public/
In this case, all user-agents are disallowed from accessing the “/private/” directory except for the “/private/public/” subdirectory.
3. Noindex vs. Disallow
It’s important to note that robots.txt and the “noindex” meta tag serve different purposes. While robots.txt prevents crawling, “noindex” instructs search engines not to index a page even if they do crawl it. Use “noindex” for pages you want to hide from search results.
4. User-Agent Specific Rules
You can create user-agent-specific rules to control the behavior of different search engine crawlers. For example:
plaintextUser-agent: GooglebotDisallow: /private/Allow: /public/User-agent: BingbotDisallow: /restricted/
This allows you to tailor the crawling behavior for each search engine.
5. Crawl Delay
While not widely supported by all search engines, you can specify a crawl delay for a user-agent. This tells the crawler to wait a certain amount of time between requests to your site. For example:
plaintextUser-agent: *Crawl-delay: 10
This instructs all user-agents to wait 10 seconds between requests. However, not all search engines adhere to this directive.
6. Robots Meta Tag
In addition to using robots.txt, you can also use the robots meta tag in the HTML of individual pages to control crawling and indexing. For example:
html
<meta name="robots" content="noindex, nofollow">
This tag instructs search engines not to index the page and not to follow any links on it.
7. Dynamic Robots.txt
In some cases, you may want to generate robots.txt dynamically based on certain conditions or user settings. This allows you to customize crawling rules based on real-time data.
8. URL Parameters
If your website uses URL parameters for sorting, filtering, or pagination, you can use robots.txt to block search engines from crawling these variations. This can help prevent duplicate content issues.
9. Handling Large Websites
For large websites with thousands of pages, managing robots.txt can be complex. Consider these strategies:
- Dynamic Rules: Generate robots.txt dynamically based on website structure and user interactions, ensuring that new content and features are properly controlled.
- Sitemap Reference: Include references to your XML sitemap(s) in robots.txt to help search engines discover and crawl your important pages efficiently.
10. User-Agent-Specific Directives
Tailor robots.txt directives for different user-agents (search engine bots) to accommodate their unique behaviors and requirements. For example:
User-agent: GooglebotDisallow: /private/Allow: /public/User-agent: BingbotDisallow: /restricted/
This allows you to fine-tune how various search engines interact with your site.
11. Subdomain Control
If your website has subdomains, remember that each subdomain can have its own robots.txt file. Ensure that subdomains are configured correctly, especially if they serve different content or have separate SEO strategies.
12. Regular Audits and Monitoring
Robots.txt files can change over time due to website updates, redesigns, or content reorganizations. Regularly audit and monitor your robots.txt file to detect issues and ensure it aligns with your SEO goals.
13. Custom Error Messages
Consider customizing error messages for blocked content. Instead of using the default “Disallow” directive, you can provide a custom message that explains why content is restricted:
User-agent: *Disallow: /private/
14. Publicly Accessible Robots.txt
Robots.txt is publicly accessible, and anyone can view it. While this is generally not a problem, avoid placing sensitive information or security-related directives in robots.txt. Use other security measures to protect such information.
15. Impact on SEO
Keep in mind that using robots.txt can affect your SEO, both positively and negatively. Properly configured robots.txt can prevent indexing of duplicate or low-quality content, but it can also block important pages inadvertently. Regularly check your website’s indexing status in Google Search Console to ensure no critical pages are unintentionally blocked.
16. SEO Plugins and CMS
If you use a content management system (CMS) like WordPress, there are SEO plugins available that simplify robots.txt management. These plugins often provide user-friendly interfaces for creating and editing robots.txt rules.
17. Use of Wildcards for User-Agents
In some cases, you might want to create rules for specific user-agents using wildcards. For example, if you want to create rules for all Googlebot variants (Googlebot, Googlebot-Image, etc.), you can do so with a wildcard:
plaintextUser-agent: Googlebot*Disallow: /private/
This rule will apply to all Googlebot user-agents.
18. Effective Use of Noindex
While robots.txt controls crawling, the “noindex” meta tag or HTTP header instructs search engines not to index a specific page. Combining robots.txt disallow rules with “noindex” directives can be a powerful way to hide content from both crawling and indexing.
19. Handling Non-HTML Content
Robots.txt is primarily used for web pages, but it can also be used to control access to other types of content, such as images, PDFs, or videos. If you want to prevent search engines from indexing certain file types, you can specify them in robots.txt:
plaintextUser-agent: *Disallow: /*.pdf$
This rule tells all user-agents to avoid indexing PDF files on your website.
20. Regularly Monitor Crawl Errors
Search engines may report crawl errors in Google Search Console related to your robots.txt file. These errors could indicate issues with your directives. Regularly review these reports to identify and address problems.
21. Consider a Default Robots.txt Rule
In some cases, you might want to have a default robots.txt rule that applies to all user-agents unless otherwise specified. This default rule can serve as a fallback:
plaintextUser-agent: *Disallow: /private/Allow: /
This rule disallows crawling of the “/private/” directory but allows crawling of the rest of the site. Specific user-agents can still override this rule with their own directives.

22. International SEO and Multilingual Websites
If you have a multilingual website, you may want to create language-specific robots.txt files. This allows you to control the crawling and indexing of content in different languages separately. For example:
plaintextUser-agent: *Disallow: /en/private/Allow: /en/public/User-agent: *Disallow: /fr/private/Allow: /fr/public/
This setup ensures that English and French language versions are treated differently.
23. Geo-Targeted Content
If your website serves different content to users in different geographic regions, you can use robots.txt to specify rules for specific user-agents and countries. This can help ensure that search engines index the appropriate content for each region.
24. Include a Reference to Your XML Sitemap
In your robots.txt file, consider including a reference to your XML sitemap(s). This helps search engines discover and crawl your important pages more efficiently. For example:
plaintext
Sitemap: https://www.example.com/sitemap.xml
This line tells search engines where to find your XML sitemap.
Robots.txt is a versatile tool that allows you to exert control over how search engines crawl and index your website’s content. Advanced usage of robots.txt involves careful planning, monitoring, and customization to suit your specific SEO needs. By implementing these advanced strategies, you can fine-tune your website’s SEO, ensure efficient indexing, and maintain control over your online presence. Regularly review and update your robots.txt file as your website evolves to keep it aligned with your SEO goals.
Robots.txt is a valuable tool in your SEO toolbox, allowing you to influence how search engines crawl and index your website. Advanced usage of robots.txt can help you fine-tune your SEO strategy, manage large websites efficiently, and tailor directives for specific search engine bots. However, it’s crucial to use robots.txt carefully, regularly audit it, and monitor its impact on your website’s SEO performance to ensure that it aligns with your goals and does not unintentionally block important content. Robots.txt is a powerful tool for controlling how search engines crawl and index your website. By understanding its advanced features and using them strategically, you can fine-tune your SEO efforts and ensure that your website is properly indexed while protecting sensitive or duplicate content. However, use caution when implementing advanced rules, as incorrect configurations can inadvertently harm your website’s visibility in search engine results. Regularly monitor your robots.txt file and its impact on search engine crawling to maintain an effective SEO strategy.